Maximizing Query Diversity for Terrain Cost Preference Learning in Robot Navigation
Joint optimization framework using variational autoencoders to enhance dataset efficiency and query diversity for preference-based terrain cost learning in robot navigation
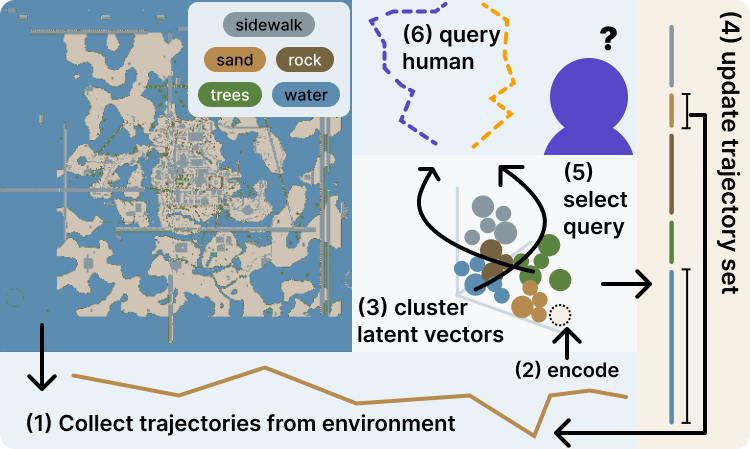
Project Overview
Duration
Research Project
Team
Multi-institutional collaboration
Status
Accepted at RO-MAN 2025
Research Team
University of Denver
Jordan Sinclair, Elijah Alabi
DEVCOM Army Research Laboratory
Maggie Wigness, Brian Reily
The MITRE Corporation
Christopher Reardon
This research introduces a joint optimization framework that increases learning efficiency by improving both the diversity of the trajectory set and the query selection strategy. Using a variational autoencoder (VAE) to encode and group trajectories based on terrain characteristics, the system identifies underrepresented terrain types and employs cluster-aware query selection to maximize information gain from human preferences.
Problem Statement
Effective robot navigation in real-world environments requires understanding terrain properties, as different terrain types impact factors such as speed, safety, and wear on the platform. While preference-based learning offers a compelling framework for inferring terrain costs through simple trajectory queries, existing approaches face significant efficiency challenges.
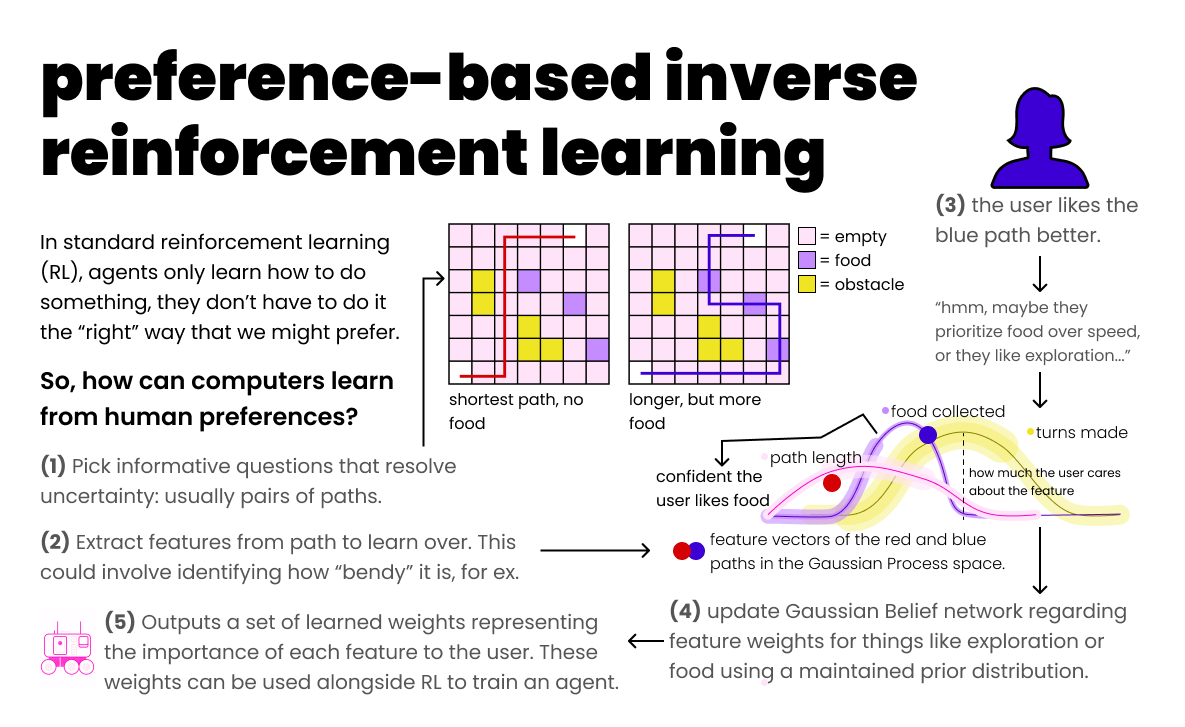
Preference-based inverse reinforcement learning framework for terrain cost learning
Core Challenges
- Redundant query selection due to limited trajectory diversity in datasets
- Query ambiguity forcing users to choose between trajectories with minimal distinguishable differences
- Inefficient learning from redundant information collection and suboptimal decision making
- Data limitations constraining the range of possible queries
- Cognitive burden on human experts providing preferences
- Uneven terrain representation in real-world environments
Technical Solution
Our approach introduces a joint optimization framework that uses a variational autoencoder (VAE) to augment the query set and enhance query selection strategy to maximize information gain and improve learning efficiency. The system integrates with APReL (Active Preference Learning library) and extends mutual information-based query acquisition by constraining the sample space and expanding the dataset.
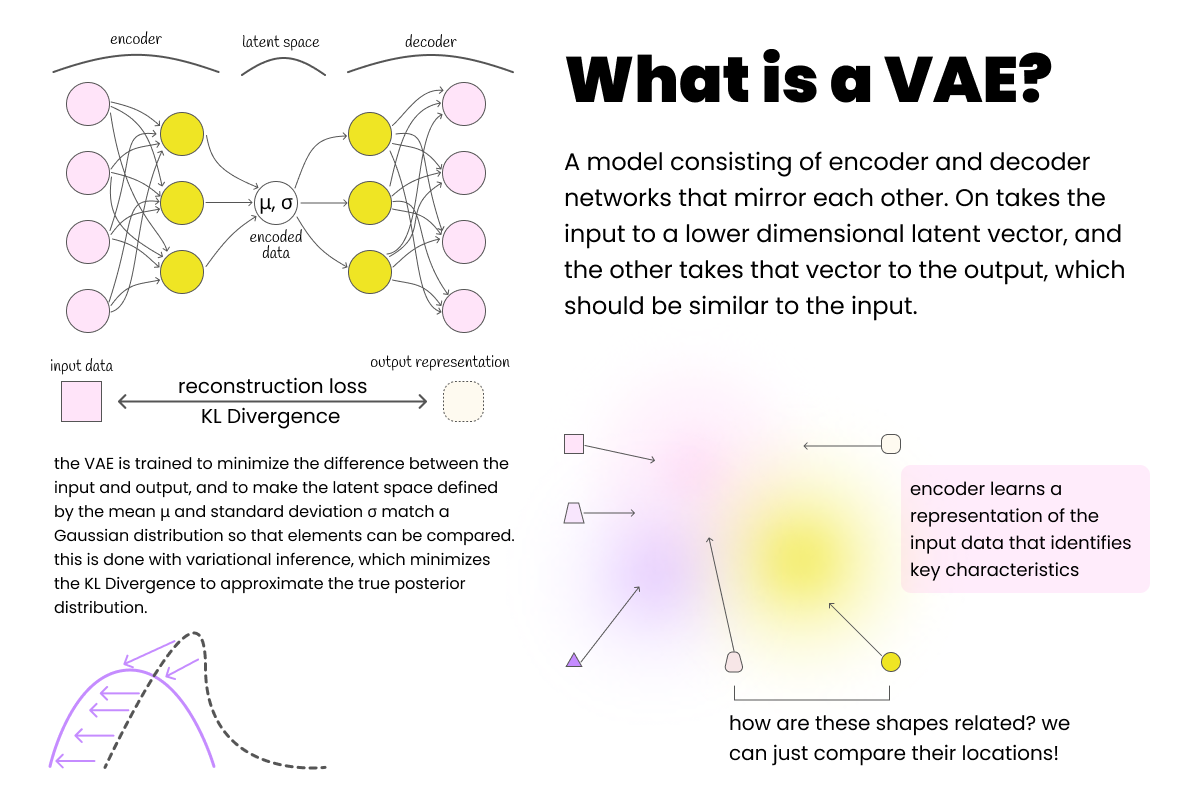
VAE architecture used for trajectory encoding and dataset augmentation
LSTM-Based VAE Architecture
Both encoder and decoder constructed from Long Short Term Memory (LSTM) layers with linear layers for appropriate output representations. Promotes pattern recognition over potentially long terrain sequences with latent dimensions proportional to number of unique terrain types.
κ-Means Clustering Strategy
Uses κ-means clustering where κ = |Γ| (number of terrain types) to create one-to-one mapping with terrain types. Clusters maintain semantic relationships and identify underrepresented terrain types through cluster size analysis for targeted dataset augmentation.
Enhanced Mutual Information Querying
Builds on mutual information-based acquisition function by limiting sample space to trajectory pairs from distinct clusters. Maximizes contrast between trajectory pairs, reducing query ambiguity and ensuring higher information gain per query.
Targeted Dataset Augmentation
Uses graph-based path planner to generate new trajectories for underrepresented clusters. Subdivides map into regions, identifies areas with highest concentration of target terrain types, and maintains consistent trajectory structures across augmented samples.
Technologies & Implementation
Experimental Setup
- • Environment: Unity-based simulation of real terrain
- • Terrain Types: Water, sand, rock, trees, sidewalk
- • Ground Truth Costs: -1.0, -0.5, 0.0, 0.5, 1.0
- • Initial Dataset: 32 trajectories, enhanced to 72
- • Trajectory Length: L=200 map cells (~40 meters)
Algorithmic Components
- • VAE Training: Reconstruction + KL-Divergence losses
- • Path Planning: Graph-based planner with NetworkX
- • Query Selection: Mutual information with cluster constraints
- • Evaluation: Simulated oracle with alignment error metric
- • Feature Representation: Terrain frequency vectors
Experimental Results & Statistical Validation
Key Experimental Findings
- 25% more convergence with ground truth costs in fixed query trials
- 40% faster convergence with statistical significance (p ≈ 0.006 < 0.05)
- Superior performance 80% of the time (8/11 tests, 1 tie, 2 losses)
- Outperformed all baseline algorithms including volume removal, Thompson sampling, disagreement selection
- Maintained correct terrain ordering while baselines converged underrepresented terrains to ~0
- Ablation study confirmed data enhancement stage improved convergence time
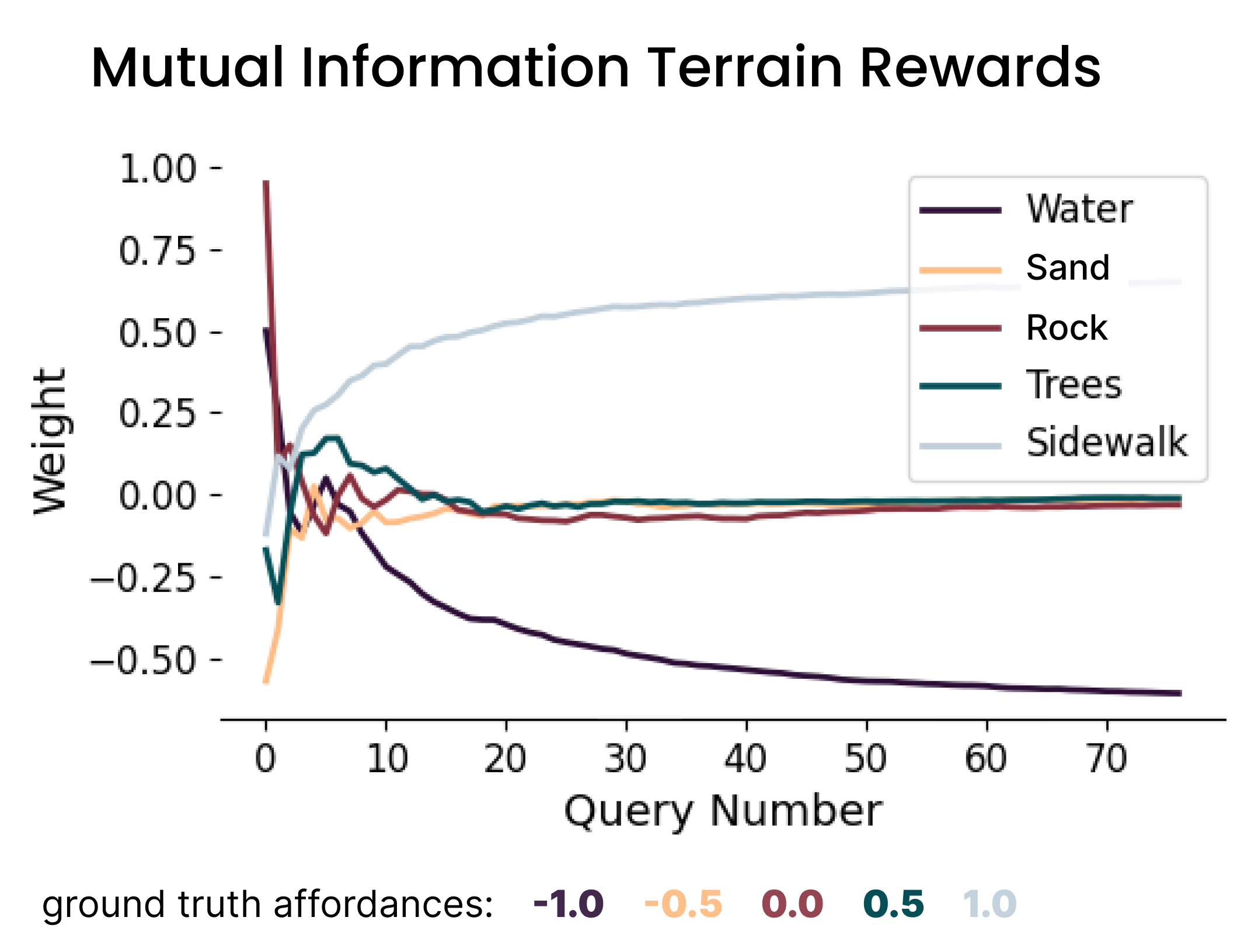
Baseline: Mutual Information querying (sand & trees converge to ~0)
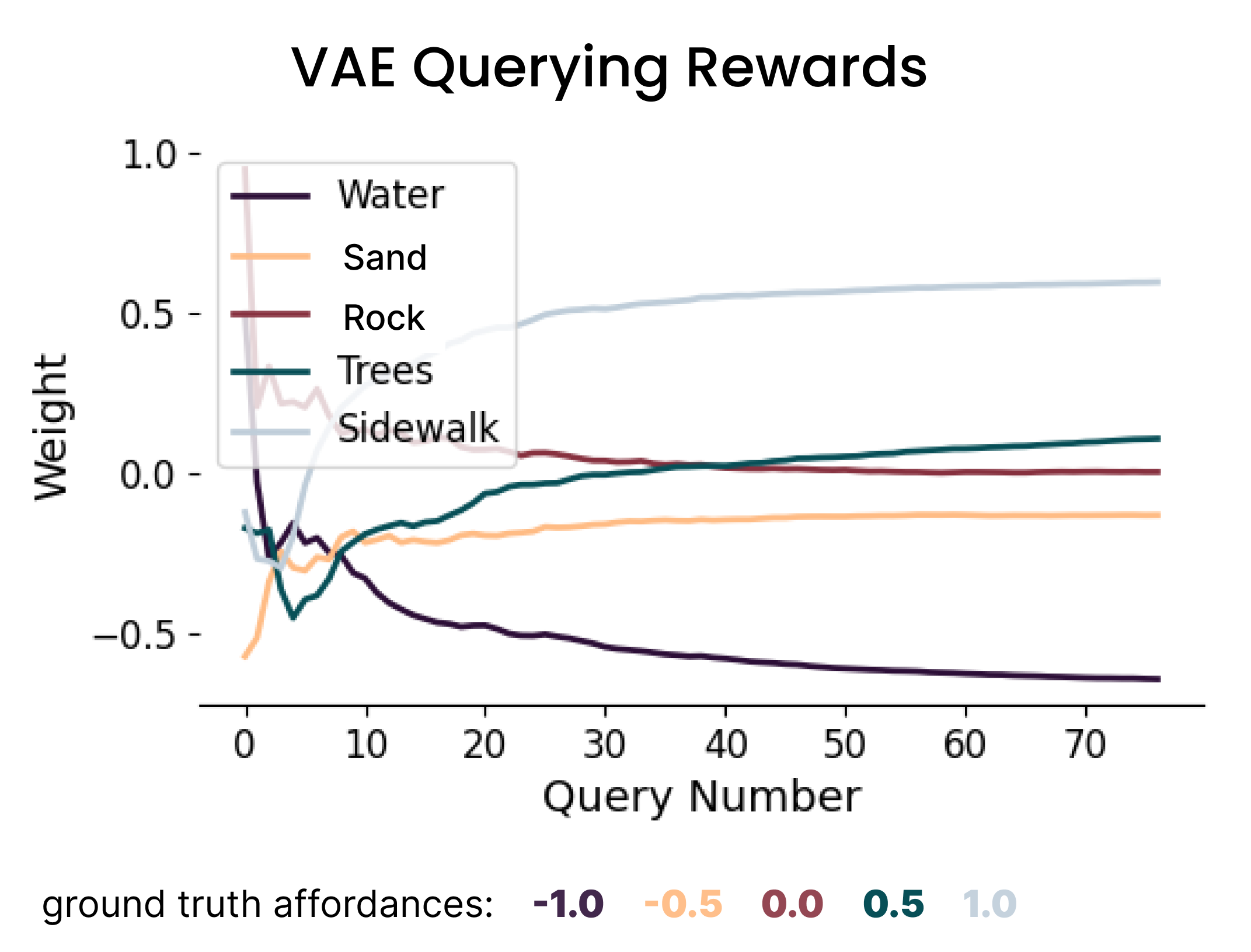
Our method: VAE querying (all terrains converge to correct values)
Experimental Design
Performance vs. Baselines
- • vs. Mutual Information: 40% faster (p < 0.05)
- • vs. Volume Removal: Lower final error
- • vs. Thompson Sampling: Superior convergence
- • vs. Disagreement Selection: Better alignment
- • Statistical Significance: p ≈ 0.006
- • Consistent Performance: 80% success rate
Critical Technical Insight
The key breakthrough was addressing terrain representation imbalance. While mutual information querying resulted in less represented terrain types (sand, trees) converging to approximately zero—indicating they were indistinguishable—our VAE-based approach enabled these terrain weights to converge to representative values in the correct ground truth order. This demonstrates the method's superior ability to maintain information diversity and avoid catastrophic information loss during preference learning.
Comprehensive Algorithm Comparison
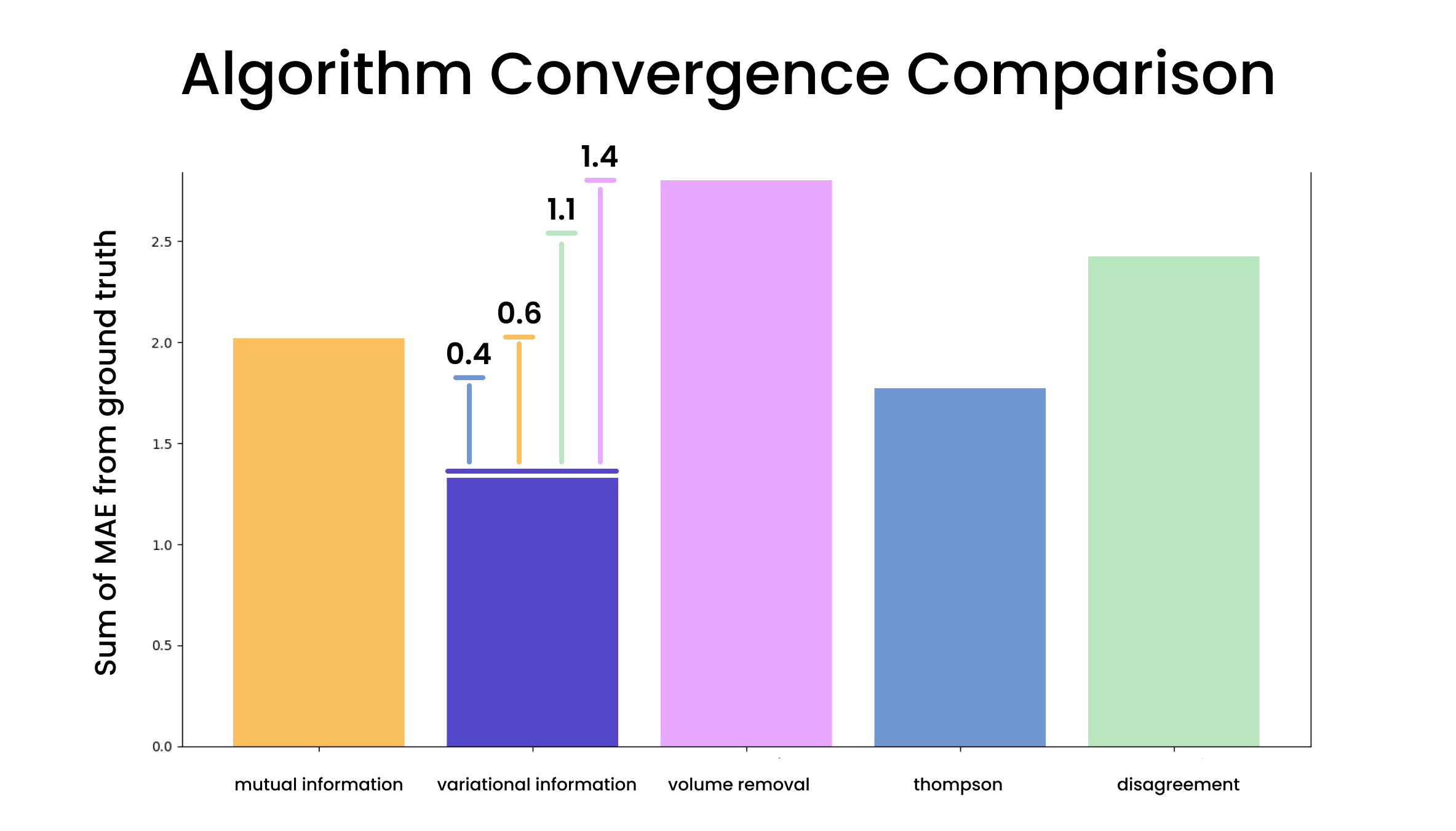
Performance comparison: Our method vs. mutual information, volume removal, Thompson sampling, and disagreement selection
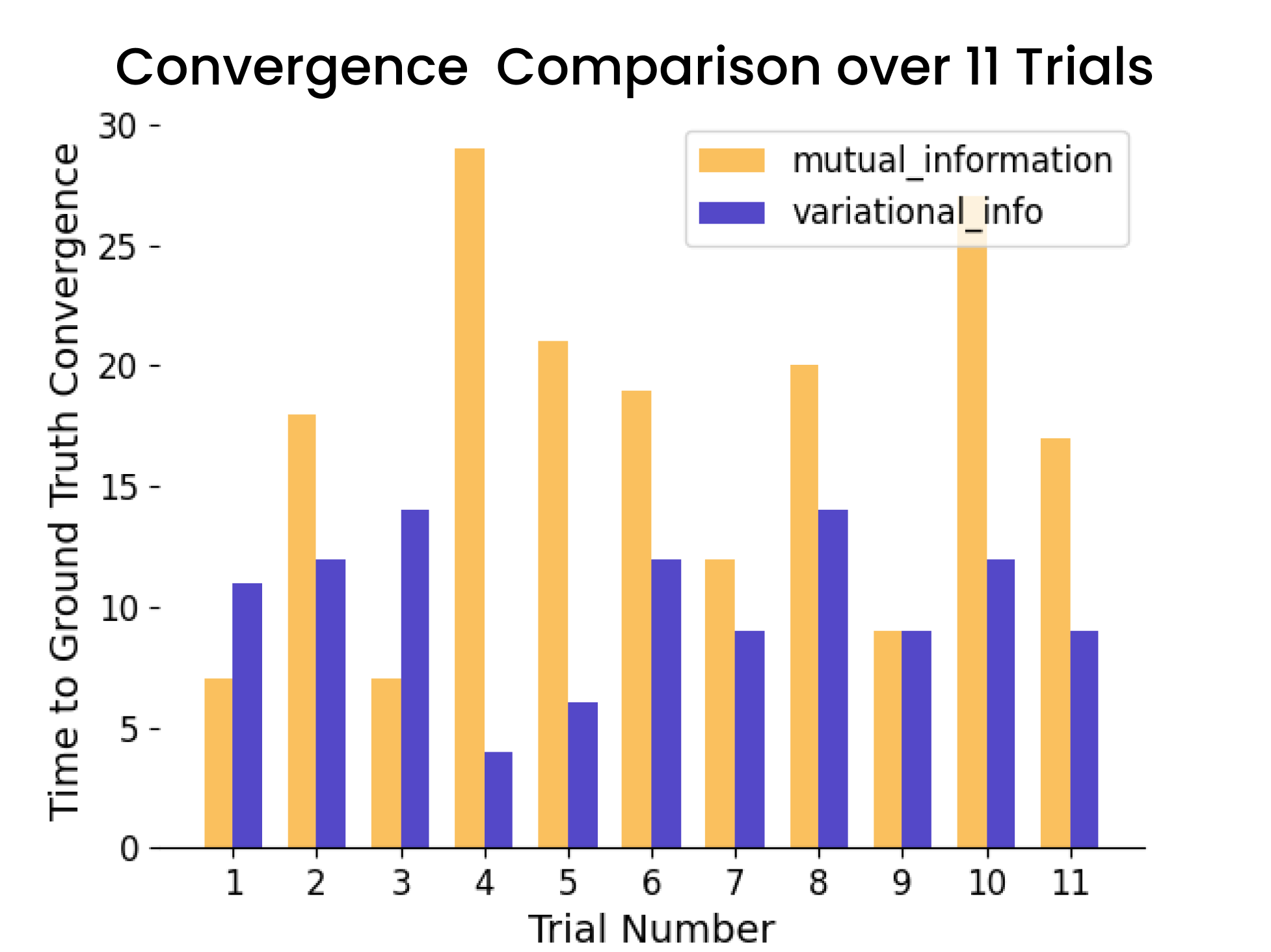
Statistical validation: 11 convergence trials (8/11 wins, 1 tie)
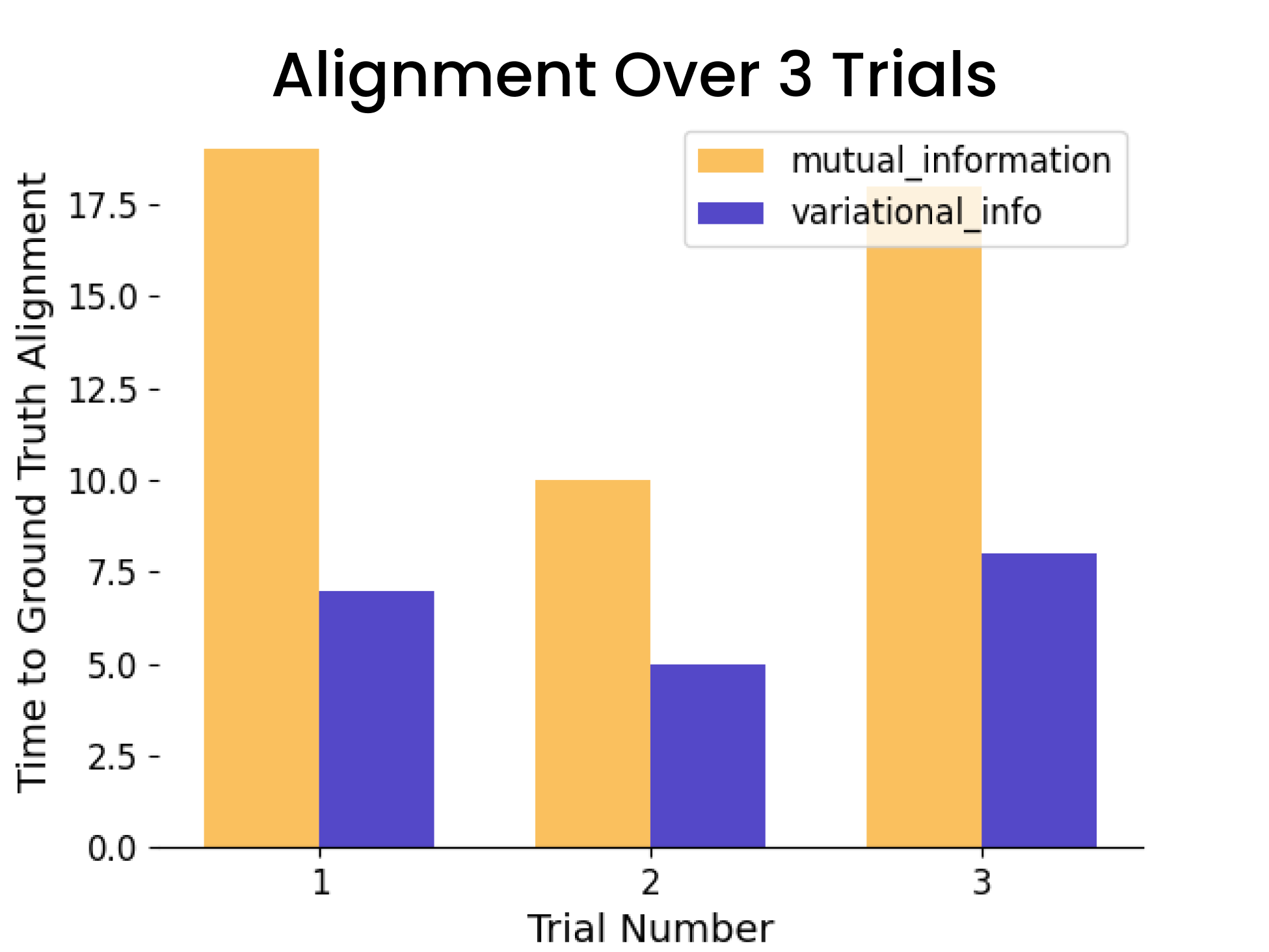
Alignment analysis: Consistent faster ground truth alignment
Ablation Study Results
VariQuery (our method name) was tested with and without the data enhancement stage to validate both components of our joint optimization framework. The ablation study confirmed that adding targeted trajectory samples to balance latent space clusters significantly improved convergence time.
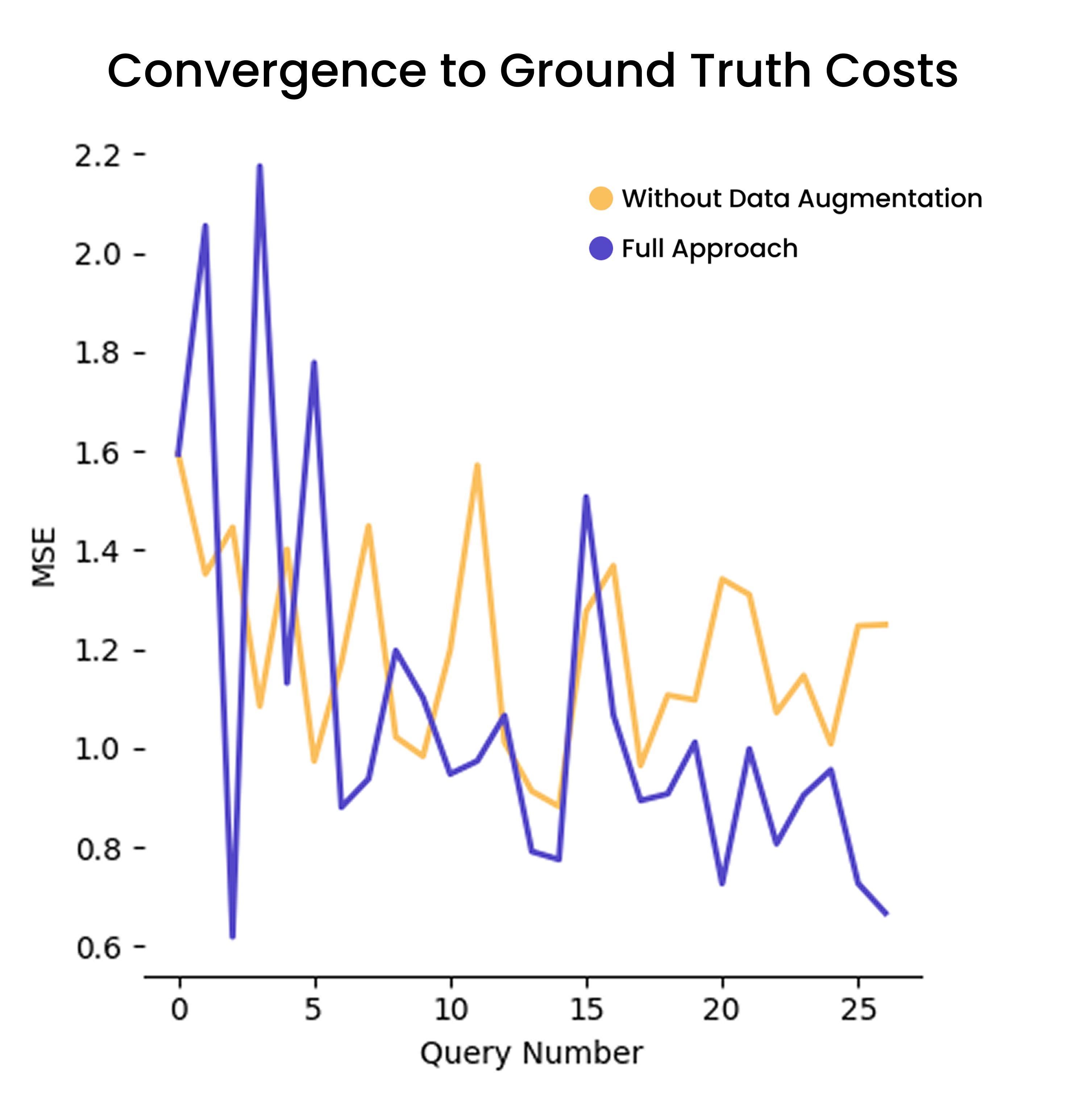
VariQuery ablation study: Validating the importance of data enhancement in our joint optimization framework
Publication & Funding
Publication Details
This work has been accepted for publication at the 2025 IEEE International Conference on Robot and Human Interactive Communication (RO-MAN 2025), a premier venue for research in human-robot interaction and autonomous systems. The research was initially presented at the InterAI workshop and in a late breaking report session at RO-MAN 2024.
Conference: IEEE RO-MAN 2025
Status: Accepted for Publication
Research Area: Preference Learning, VAE, Robot Navigation
DOI: To be assigned
Previous Presentations:
• RO-MAN 2024 InterAI Workshop
• RO-MAN 2024 Late Breaking Report Session
Impact: Statistically significant improvements
Research Funding
This work was supported by Army Research Office (ARO) under grantW911NF-22-2-0238, demonstrating the military and civilian applications of enhanced preference-based learning for autonomous navigation systems.
Research Impact & Future Applications
This research establishes a foundational framework for improving preference-based learning efficiency across diverse robotic applications. The joint optimization approach—combining dataset enhancement with intelligent query selection—has broad implications for human-robot interaction and autonomous system development.
Research Contribution Significance
This work addresses a fundamental challenge in preference-based inverse reinforcement learning: how to learn efficiently from limited human feedback. By achieving 40% faster convergence with statistical significance, the methodology reduces the cognitive burden on human experts while improving learning outcomes—a critical advancement for practical human-robot collaboration.
Military & Defense Applications
Army Research Office funding highlights mission-critical applications including:
- • Autonomous ground vehicle navigation in combat environments
- • Search and rescue operations in challenging terrain
- • Supply chain logistics in varied geographical conditions
- • Reconnaissance missions requiring adaptive path planning
Civilian & Commercial Impact
The methodology extends to numerous civilian applications:
- • Autonomous vehicle navigation optimizing for safety and efficiency
- • Agricultural robotics adapting to soil and crop conditions
- • Environmental monitoring in diverse ecosystems
- • Disaster response robotics navigating debris and obstacles
Future Research Directions
Current Research: Robot Aesthetic Preference Learning
Building on this terrain cost learning foundation, current research explores robot aesthetic preference learning using images. This extension applies VAE-based encoding to visual preferences, modeling aesthetic decisions through APReL framework. While the current implementation focuses on core VAE functionality, future iterations will integrate the data enhancement and clustering strategies proven effective in this terrain research.
Multi-Modal Integration
Combining terrain, visual, and tactile preferences for comprehensive environmental understanding
Real-Time Adaptation
Online learning systems that adapt VAE representations as new terrain types are encountered
Cross-Domain Transfer
Applying learned preferences across different environments and robot platforms
Technical Research Extensions
Methodology Enhancements
- • Hierarchical VAE architectures for multi-scale terrain understanding
- • Adaptive clustering algorithms that discover optimal κ values
- • Uncertainty quantification in preference predictions
- • Active learning strategies beyond mutual information
Broader Applications
- • Human-robot collaborative planning incorporating diverse preferences
- • Multi-agent systems with shared preference learning
- • Personalized robotics adapting to individual user preferences
- • Safety-critical systems with preference-aware risk assessment
Long-Term Research Vision
This research contributes to the broader goal of human-aligned autonomous systems that can efficiently learn and adapt to human preferences across diverse domains. By demonstrating statistically significant improvements in preference learning efficiency, this work paves the way for more practical human-robot collaboration in real-world applications where expert time is limited and accuracy is critical.